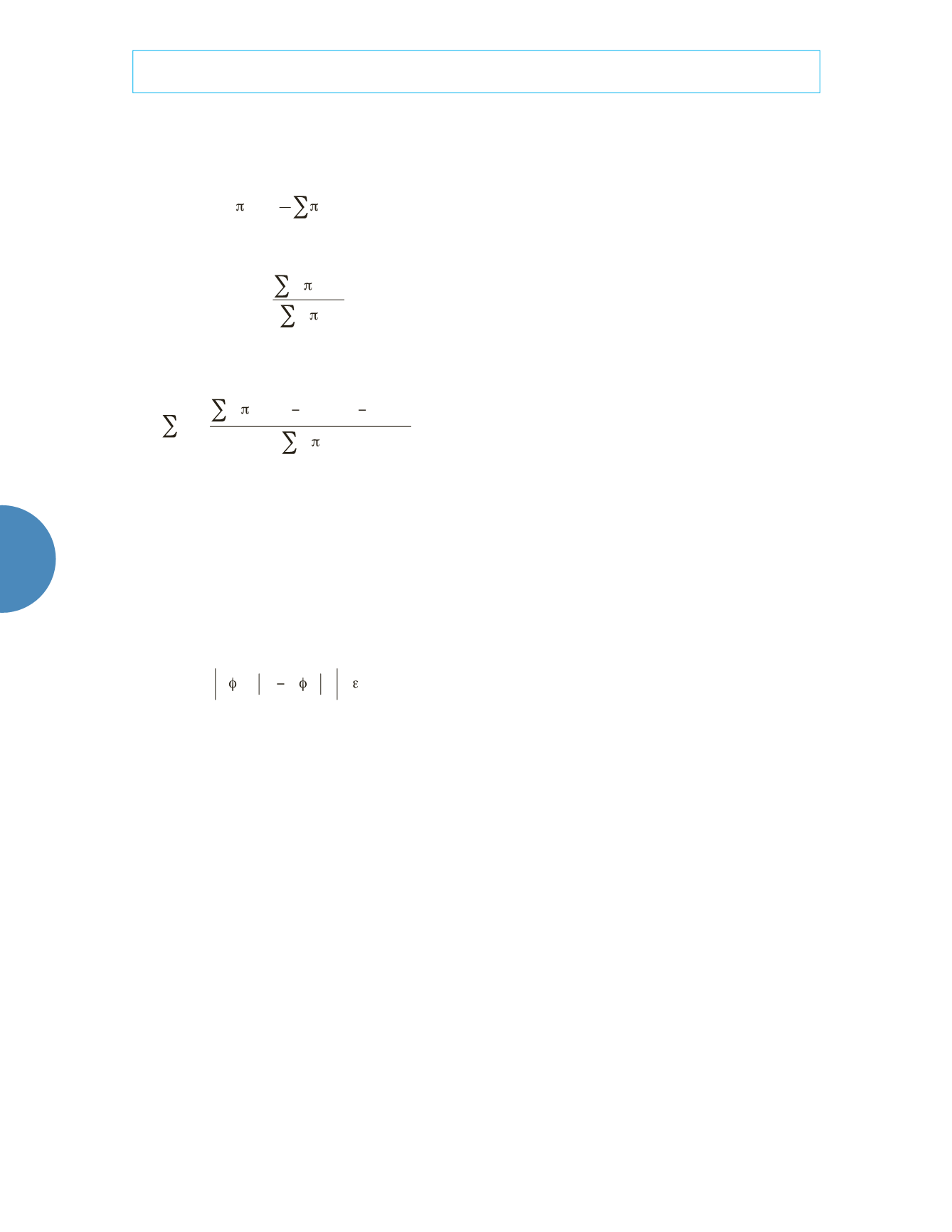
10
Tecnología y Ciencias del Agua
, vol. VIII, núm. 4, julio-agosto de 2017, pp. 5-18
Buendía-Espinoza
et al
.,
Identificación de cambios en la ciclogénesis del Atlántico Norte mediante un modelo de mezclas Gaussianas
•
ISSN 2007-2422
El paso-M tiene una solución analítica:
j
t
+
1
( )
=
1
n
ij
t
+
1
( )
i
=
1
n
μ
j
t
+
1
( )
=
ij
t
+
1
( )
x
i
i
=
1
n
ij
t
+
1
( )
i
=
1
n
y
=
ij
t
+
1
( )
x
i
μ
j
t
+
1
( )
(
)
x
i
μ
j
t
+
1
( )
(
)
T
i
=
1
n
ij
t
+
1
( )
i
=
1
n
j
t
+
1
( )
(5)
El algoritmo EM comienza con una esti-
mación inicial del valor de los parámetros
f
,
llamada
f
(
t
)
. Luego, mediante las ecuaciones
(4) y (5), se estiman los valores de los nuevos
parámetros, llamado
f
(
t
+1)
. El proceso se repite
hasta que la diferencia entre dos evaluaciones
sucesivas de la log-verosimilitud sea menor que
una épsilon dada
e
, es decir:
l
t
+
1
( )
x
(
)
l
t
( )
x
(
)
<
(6)
en este trabajo se fijó
e
= 1 x 10
-3
. Este resultado
depende de la selección de los parámetros ini-
ciales (Seidel, Mosler, & Alker, 2000).
b) Inicialización en el algoritmo EM
El algoritmo EM es un procedimiento iterativo
de maximización que depende del valor inicial
de los parámetros, pues la función de verosimi-
litud puede tener máximos locales (McLachlan
& Peel, 2000). Por lo tanto, una buena iniciali-
zación es crucial para encontrar los estimadores
de máxima verosimilitud.
Se han sugerido diferentes procedimientos
de inicialización en la literatura (Figueiredo &
Jain, 2000; Maitra, 2009); sin embargo, ningún
método supera a los demás. En este trabajo
se utilizó el procedimiento de Fraley, Raftery,
Murphy y Scrucca (2012), implementado en la
biblioteca de funciones de R (R Core Team, 2016)
mclust
, para encontrar los valores iniciales de
los parámetros que permiten obtener el valor
máximo en el marco de mezclas Gaussianas
multivariadas.
Identificación del número óptimo de
componentes o grupos
Hay una vasta lista de literatura dedicada al
tema de la elección de
K
(número de compo-
nentes). McLachlan y Peel (2000) proporcionan
una interpretación detallada de los diferentes
enfoques disponibles para abordar este pro-
blema. La mayoría de los métodos destinados
a la estimación de
K
se divide por lo general
en dos categorías: modelos basados en el prin-
cipio de la parsimonia y modelos basados en
procedimientos de prueba, ambos sustentados
en la función de log-verosimilitud. Sin embargo,
en este estudio,
K
se determinó mediante un
método heurístico, conocido como partición
alrededor de los medoides (PAM, por sus siglas
en inglés, Partitioning Around Medoids).
El algoritmo de la PAM se basa en la forma-
ción de
K
particiones u objetos representativos
(medoides) de
n
observaciones de un conjunto
de datos. Un medoide se define como la obser-
vación de un agrupamiento, cuya diferencia pro-
medio, con respecto a todas las observaciones en
el grupo, es mínima. Se eligen aleatoriamente
K
medoides de un conjunto de datos. El medoide,
que representa un grupo, se ubica en el centro
del grupo. Los objetos restantes se agrupan con
el medoide al que son más similares, basándo-
se en la distancia entre el objeto y el medoide.
La estrategia, entonces, es reemplazar uno de
los medoides por los no medoides, siempre y
cuando la calidad del agrupamiento mejore.
Esta calidad es estimada usando una función
de costo que mide el promedio de disimilaridad
o diferencia entre un objeto, y el medoide de su
grupo (Kaufman & Rousseeuw, 2005).
El método PAM genera una gráfica, conocida
como gráfica de “siluetas”. Para cada obser-
vación se muestra una medida que indica la
calidad de la clasificación. Valores cercanos a 1
indican que la observación está bien clasificada


